Quantum Computing: What Every CIO Should Understand Before Investing
Quantum will not replace the classical cloud. It will enter the enterprise as a specialized accelerator within a hybrid, distributed computing architecture.
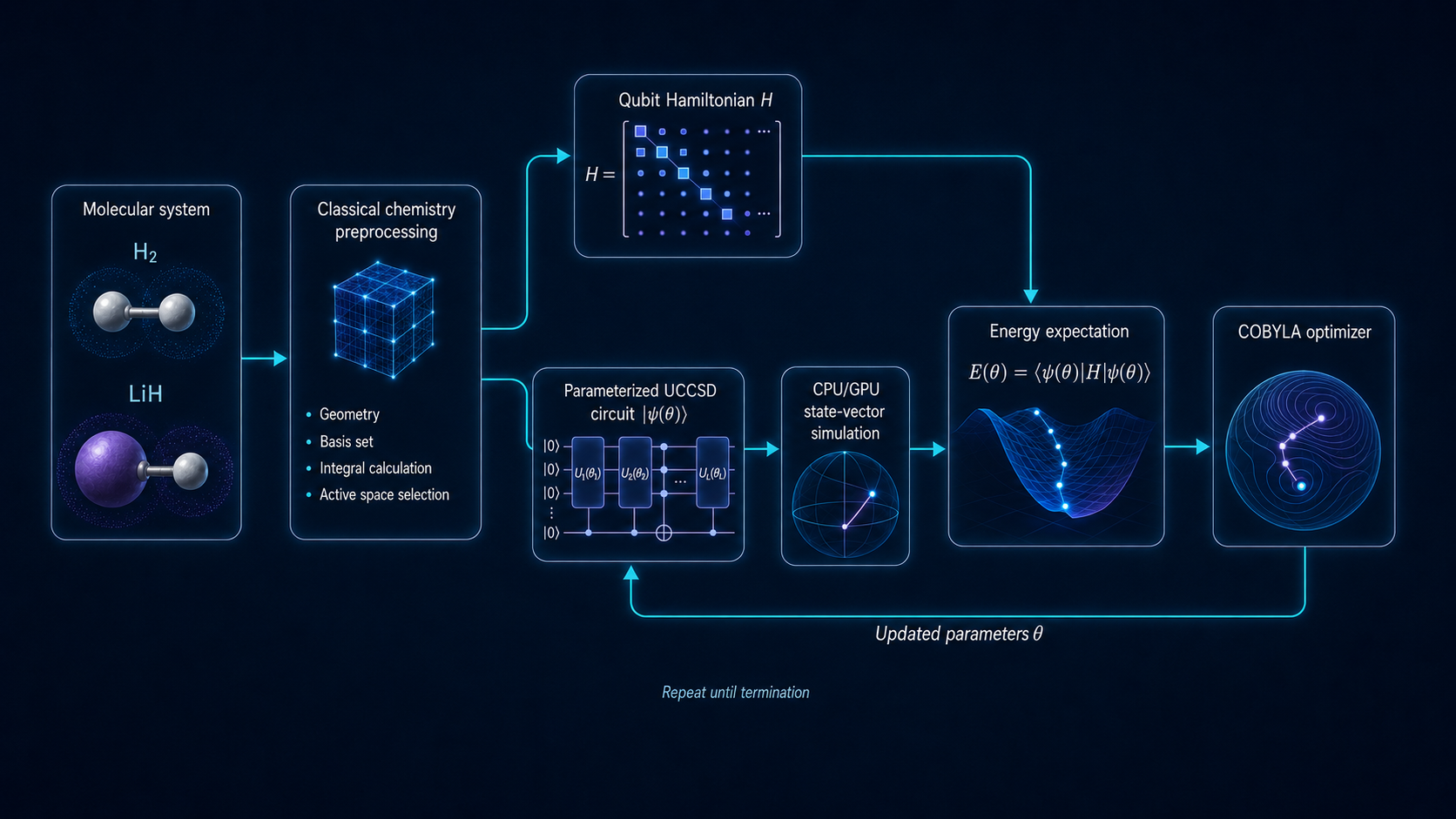
A hybrid quantum-classical workflow for molecular simulation
Most executive conversations about quantum computing begin with the wrong question: When will quantum computing be ready?
For a CIO, the more useful question is: What capabilities should we build now that will remain valuable regardless of when fault-tolerant quantum computing arrives?
That change in perspective matters. It moves the conversation away from predictions and marketing claims and toward business value, architectural readiness, organizational learning, and investment discipline.
Quantum computing is advancing, but its commercial maturity varies considerably by workload. Some organizations are conducting credible research in areas such as chemistry, materials science, optimization, and financial modeling. Others are buying access, announcing partnerships, or launching proofs of concept without a clear connection to a business problem.
The responsible position is neither to dismiss quantum computing nor to make a large speculative commitment. It is to build informed optionality: understand where quantum may matter, develop the ability to test it, and avoid architecture decisions that create unnecessary dependency before the technology and use cases mature.
Quantum computing is an accelerator, not a replacement for cloud computing
Quantum computers are not designed to replace the systems that run enterprise applications, databases, APIs, collaboration platforms, analytics environments, or AI services. They are specialized systems intended to address particular classes of computational problems.
The more realistic future is heterogeneous computing: CPUs, GPUs, and quantum processing units, or QPUs, working together. CPUs will continue to orchestrate applications and perform general-purpose processing. GPUs will continue to accelerate simulation, AI, and other parallel workloads. QPUs may eventually accelerate selected parts of problems for which quantum algorithms offer a meaningful advantage.
This is not merely a conceptual model. NVIDIA describes CUDA-Q as a programming model for hybrid applications in which CPUs, GPUs, and QPUs operate together. IBM similarly frames its direction as “quantum-centric supercomputing,” where quantum resources extend classical systems rather than replace them.
For CIOs, the implication is direct: quantum computing should be evaluated as one component of a broader computing portfolio. A quantum strategy that is disconnected from cloud architecture, accelerated computing, data platforms, security, and application modernization is unlikely to produce durable value.
What I learned by building the workflow
I studied physics, and the Schrödinger equation has always fascinated me—not only for its mathematical elegance, but also because it connects an abstract description of a quantum state to physical outcomes we can observe. Molecular simulation gave me a practical way to return to that interest through the lens of my work in cloud computing: what classical infrastructure, software, and operating discipline are required to formulate, execute, and evaluate a quantum workload responsibly?
To move beyond theory, I built a public, containerized molecular-simulation blueprint using NVIDIA CUDA-Q and cuQuantum. I deployed and tested it on an Akamai Cloud instance with an NVIDIA RTX PRO 6000 Blackwell GPU.
The objective was deliberately narrow. It was not to claim quantum advantage, position Akamai as a dedicated quantum cloud, or suggest that a GPU is a substitute for a QPU. The purpose was to examine the engineering stack that organizations can use today while quantum hardware continues to mature.
The workflow used:
CPUs for orchestration, chemistry preprocessing, and optimization control;
CUDA-Q as the hybrid programming model;
a CPU state-vector simulator and an NVIDIA GPU simulator as alternative execution backends;
hydrogen and lithium hydride molecular problems as test cases; and
containers, Terraform, and Ansible to separate the portable application from provider-specific deployment.
The initial lithium hydride results appeared to show that the GPU completed the workload faster than the CPU, but none of the runs reached the defined chemical-accuracy threshold. One seed also produced a much worse result than the others. Instead of treating the faster wall time as the main conclusion, I investigated why the scientific result was unstable.
The investigation found an experimental-design defect. The lithium hydride Hamiltonian represented an active space of two electrons and five spatial orbitals, requiring 10 qubits. The UCCSD circuit, however, had been dimensioned from the full molecule and used 12 qubits and 92 parameters. The Hamiltonian and circuit were not describing the same problem dimensions.
I then ran a controlled follow-up using five seeds across three arms:
| Experimental arm | Circuit | Mean objective-function evaluations | Mean wall time | Accuracy outcome |
|---|---|---|---|---|
| Legacy circuit on GPU FP64 | 12 qubits, 92 parameters | 1,500; cap reached in 5/5 runs | 1,068.8 ± 3.5 seconds | 0/5 reached chemical accuracy |
| Matched circuit on GPU FP64 | 10 qubits, 24 parameters | 1,030; all runs terminated below the cap | 719.4 ± 5.5 seconds | 5/5 reached chemical accuracy |
| Matched circuit on CPU | 10 qubits, 24 parameters | 1,055.2; all runs terminated below the cap | 773.4 ± 30.1 seconds | 5/5 reached chemical accuracy |
Wall time is reported as mean ± standard error; n=5 per arm.
The legacy arm’s median absolute error was 6.92 millihartree. Its mean was 31.18 millihartree because seed 44 finished 126.01 millihartree from the stored reference. Leading with the median is important: the mean alone would obscure the fact that one poor basin drove much of the reported error.
The matched runs tell a different story. All ten reached the 1.6-millihartree chemical-accuracy threshold. Their final energies agreed from run to run—and between CPU and GPU—to approximately 10⁻¹³ hartree.
That is evidence of numerical reproducibility, not independent proof of 10⁻¹³ hartree accuracy. The stored CASCI reference, -7.882164 hartree, was retained to only six decimal places. The matched result, approximately -7.882164029897 hartree, therefore appears about 2.99 × 10⁻⁵ millihartree below the stored reference. That tiny residual is governed by reference quantization. The defensible accuracy statement is that every matched run reached chemical accuracy; the stronger 10⁻¹³ figure describes agreement among the runs and backends.
For this two-electron active-space problem, the corrected result is technically expected. Singles and doubles cover the available excitation ranks from the reference state. Once the circuit dimensions matched the Hamiltonian, the optimizer no longer had to navigate the unnecessary degrees of freedom in the legacy circuit.

The corrected 10-qubit, 24-parameter circuit reached chemical accuracy on every seed. The legacy 12-qubit, 92-parameter circuit did not.
The matched GPU arm completed in approximately 32.7% less wall time than the legacy GPU arm. That was a benefit of correcting the problem formulation: the matched circuit was smaller and required fewer objective-function evaluations. It should not be presented as evidence of general GPU acceleration.
For the same matched circuit, the CPU was faster on two of the five seeds. Across all five runs, the ratio of mean CPU time to mean GPU time was 1.075. Given the small sample and variation in CPU wall time, the result is best described as near parity—not as a consistent GPU advantage. At 10 qubits, fixed software and orchestration overhead can dominate the small state-vector calculation.
The more durable result is portability. CPU and GPU FP64 produced numerically equivalent final energies for all five matched seeds, with a maximum difference of approximately 6.6 × 10⁻¹³ hartree. The workflow could move between backends without changing the scientific result.

Building—and then correcting—the workflow reinforced four lessons that apply well beyond quantum computing:
Scientific and architectural correctness come before infrastructure optimization. A faster execution of the wrong formulation does not create business value.
A single successful run is not sufficient evidence. Multiple seeds exposed instability that would have been hidden by a selected demonstration.
Aggregate averages can conceal operationally important variation. Per-run and paired results matter, especially when a small sample changes direction.
The engineering stack matters before the QPU does. Organizations need orchestration, accelerated classical compute, observability, controlled environments, cost controls, and portable software regardless of which quantum hardware eventually proves useful.
The experiment did not establish a quantum advantage. It established something more practical for an enterprise technology leader: quantum readiness begins with the quality of the classical engineering and decision process surrounding the quantum workload.
How quantum fits into distributed cloud
Quantum computing will not make workload-placement decisions simpler. It will add another specialized resource to an already heterogeneous environment.
An enterprise quantum workflow may need to coordinate:
data stored in an enterprise environment;
CPUs for application logic and orchestration;
GPUs for simulation, optimization, error mitigation, or AI-assisted scientific work;
QPUs accessed through a remote service;
regional infrastructure selected for data governance, cost, availability, or performance reasons; and
observability and security controls spanning the entire workflow.
This is where distributed cloud becomes strategically relevant. The value is not that every quantum workload should run at the edge. Molecular simulation, for example, is generally a batch-oriented scientific workload rather than a latency-sensitive edge application. The value is that enterprises need the freedom to place each part of a heterogeneous workflow where it makes the most technical, economic, and regulatory sense.
The follow-up experiment made that placement decision concrete. At the time of the run, the same Blackwell instance cost $3.00 per hour in the selected U.S. region and $4.50 per hour in Jakarta. The measured VM lifetime was 3 hours, 54 minutes, and 45 seconds, producing an infrastructure charge of $11.74. The equivalent Jakarta charge would have been $17.61. Region selection did not change the controlled comparison, but it materially changed its cost.
Portability is therefore an investment-protection mechanism. A provider-agnostic application layer, containerized runtime, open interfaces, and infrastructure-as-code allow an organization to change classical infrastructure or connect to different quantum backends without redesigning the entire workflow.
No architecture can eliminate switching costs completely. But enterprises can avoid creating unnecessary dependency before the market has established which QPU modalities, software frameworks, and service providers will deliver sustained value.
A practical investment framework for CIOs
Before approving a material quantum-computing investment, a CIO should be able to answer six questions.
| Decision question | Evidence leadership should require |
|---|---|
| What business problem are we trying to solve? | A defined operational, scientific, financial, or customer outcome—not a general desire to “explore quantum.” |
| Why might quantum be relevant? | A credible explanation of the computational bottleneck and why classical methods may become insufficient. |
| What can be learned with current infrastructure? | A plan using simulators, CPUs, GPUs, and available QPU access to validate the workflow and develop internal capability. |
| How will success be measured? | Accuracy, time to solution, repeatability, total cost, scalability, and business impact—not qubit count alone. |
| How portable is the architecture? | Separation between application logic, orchestration, provider infrastructure, and hardware-specific backends. |
| What decision will the experiment enable? | A clear stage gate: stop, continue learning, expand the use case, or prepare for production integration. |
This framework changes the objective of an early quantum program. The first goal is not to achieve production-scale quantum advantage. It is to reduce uncertainty at a controlled cost.
That can include identifying one or two domain-specific problems, developing a small cross-functional team, testing open and portable tools, establishing benchmark discipline, and documenting what would have to become true for the use case to justify further investment.
Keep quantum computing and post-quantum security separate
CIOs should also distinguish between two related but different priorities. The first is using quantum computing to solve business or scientific problems. This remains an emerging opportunity that should be managed through focused experiments and staged investment.
The second is protecting current systems and data from future quantum-enabled attacks. Post-quantum cryptography is a security and risk-management program. NIST has already finalized initial post-quantum cryptographic standards, which means organizations can begin inventorying cryptographic dependencies, evaluating vendor roadmaps, and improving crypto-agility.
The timelines, budgets, owners, and success measures for these two initiatives should not be combined. An organization may reasonably move cautiously on quantum-computing applications while acting more urgently on post-quantum security.
What a responsible quantum strategy looks like
A responsible strategy does not begin with a large hardware commitment or a broad innovation mandate. It begins with a business problem, a learning objective, and an architecture that preserves choices.
For most enterprises, the near-term priorities should be:
identify a small number of problems where quantum methods may eventually matter;
build competency in hybrid quantum-classical workflows;
use current CPU and GPU infrastructure to test algorithms and integration patterns;
measure accuracy, reproducibility, performance, and cost separately;
keep the core application portable across infrastructure and hardware backends; and
expand investment only when the evidence supports the next stage.
This approach is intentionally measured, but it is not passive. Waiting until quantum computing is fully mature could leave an organization without the skills, data preparation, architecture, partnerships, or governance required to use it. Investing indiscriminately today could produce expensive demonstrations with little lasting value.
The better path is to build capabilities that are useful now and preserve options for later.
Quantum computing will not replace the classical cloud. It will become part of a more diverse computing environment—one in which CPUs, GPUs, QPUs, networks, and distributed cloud resources are coordinated around the needs of the workload.
The CIO’s responsibility is not to predict the precise date when quantum advantage will arrive. It is to ensure that the organization can recognize meaningful progress, test it responsibly, and adopt it without surrendering architectural control.
That is what it means to become quantum-ready.